capabilities overview
understanding data devOps
Classic devOps is defined as a set of software development practices that combine software development and information technology operations to shorten the systems development life cycle while delivering features, fixes, and updates frequently in close alignment with business objectives. data devOps extends these principles to activities that are unique to data centric operations, and for which most organizations rely on expansive and expensive glue code, ever increasingly complex data pipeline jungles and ETL processes, or the promise of an eventual all unifying data model centralized in a data lake or warehouse that will one day deliver on its full promise. Our fully managed service empowers organizations to focus on their business questions first, and start building and operationalizing data centric applications such as ML, today.

core capabilities
To address these specific issues of data centric operations datagenous provides the capabilities to:
- identify, acquire, and unify data resources
- compose, define, and tokenize data service workflows
- comprehend data and control flows using retrospective analysis
- apply rules for data quality and augmentation (e.g.inference, mapping)
- apply feedback loops with advanced computational models (e.g. ML, AI)
- consolidate, federate, or distribute services
and two cross cutting capabilities:
- orchestrate and manage data flow dependencies
- govern data services both inside and outside the enterprise firewall
These capabilities can be used in combination to support the the data devOps lifecycle.
capability details
1. identify, acquire, and unify data resources
Teams can work with datagenous by focusing on the minimum client system interface requirements that satisfy an initial data flow, a minimally viable implementation (MVI). The MVI establishes the business context for unifying data resources. datagenous allows users to identify, acquire, and unify resources with differing sample rates from millisecond streams, generated by sensors, to large archival or reference datasets which may only by occasionally updated.
datagenous resources can be of one of two types:
- local - in which authentication and credential criteria are managed within the datagenous service realm creating repositories
- remote via an agent
datagenous provides resource acquisition interfaces for:
- REST APIs
- MQTT/WSS streams
- External stores such as Google Cloud Storage, S3, Azure, etc.
- ODBC
- SPARQL, Graph Store Protocol and GraphQL endpoints
- local MySQL, PostgreSQL, and ODBC data sources
- HDT archives
Once defined within the datagenous environment, developers and SMEs can use datagenous to model and manipulate information as if all data across the enterprise, cloud, or partner services (e.g. extranet or partner provided API) were centralized and homogeneous, without the need for additional infrastructure or glue code. Teams can access resources through:
- JavaScript API which affords access through MQTT and WebSocket connections
- standard W3C HTTP-based protocols for SPARQL, GSP , and GraphQL
- MQTT/WSS
Detailed API documentation, and technical resources for our service can be found here.
2. compose, define, and tokenize data service workflows
One can use datagenous to:
- Construct and map schema on the fly
- Define and attach universal identifiers (UID), e.g. tokenize things that have meaning in the business context
- Define links between UIDs (tokens)
- Compose schemas and data services from published component data services (data service APIs)
As an example, you can use datagenous to create digital twins:
- You can represent that digital twin using a uniquely identified tokenized digital asset.
- You can define a data flow reconciling and integrating data across multiple systems(e.g. quality reporting, product lifecycle management, procurement and fulfillment)
- You can publish the outputs of the data flow as a data service consumable by external clients.
3. comprehend data and control flows using retrospective analysis
datagenous provides capability for continuous integration (CI) of data services and flows utilizing a practice we refer to as retrospective late binding (RLB). This practice is powered by our schemaless, RDF versioned data access layer that decouples data flows from underlying control flows. This decoupling enables development teams and SMEs to logically unify semantic structures without worrying about breaking brittle schema and underlying data structures.
RLB allows for the incremental refining of data models, for the reconstruction and alignment of legacy models, and the integration of new models and external resources.
4. apply rules for data quality, validation, inference, and mapping
datagenous provides several capabilities to ensure that data conforms to quality criteria:
- datageneous supports introspective statistical analysis of data elements in your workflows (e.g. duck typing)
- datageneous datageneous supports conformance with enterprise data dictionaries though inference and validation rules
- datageneous allows for rapid and flexible mapping of data elements across domains (schemas, vocabulaires, and ontologies)
5. apply feedback loops with advanced computational models
- datagenous is designed to lower the barriers to adopt, develop, integrate and operationalize, of cognitive assistance (CA) such as ML models into data flows. Built on top of a jupterylabs, you can natively access models from within the datagenous service.
- Analytic models, like other data services, can be deployed and managed at many layers in the architecture from edge to center to flexibly layer analytics.
- datagenous orchestrates and manages data services and versions providing a coherent, repeatable framework that reduces the compeixity of managing evolving models.
6. consolidate, federate, or distribute data services
We support centralized, federated, and distributed deployment environment topologies. Because datagenous decouples data control flows from data flows, the process of service operationalization (SO) is able to support a wide variety of data service deployment architectures, as well as the ability to rapidly adapt to changing computing infrastructure environments. This includes the ability to provide optimizations through materialized data services and layered analytics.
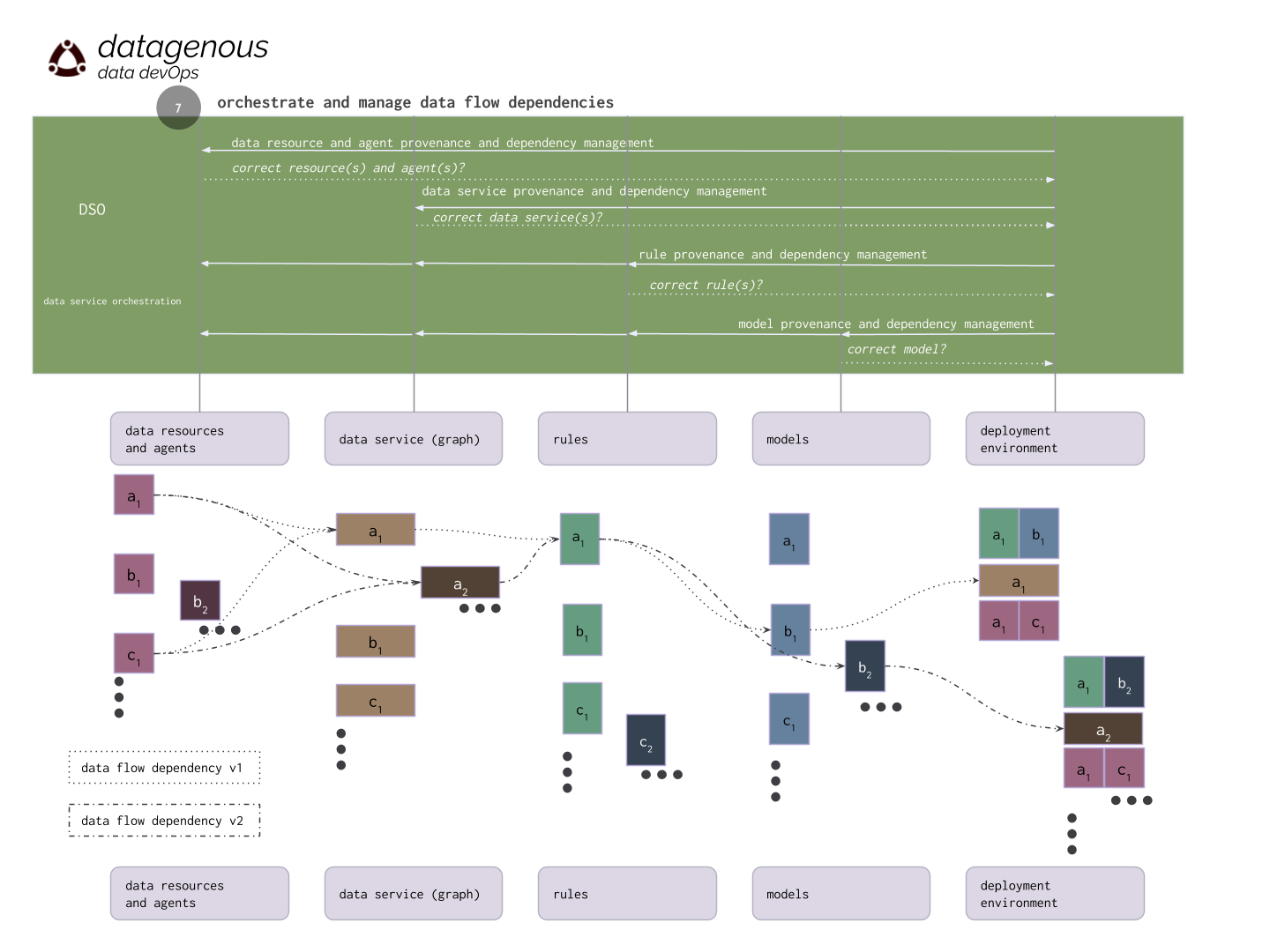
7. orchestrate and manage data service dependencies
datagenous enables you to coordinate the relationship between resources, data services, rules, and ML models as data inputs and schema change, and ML models adapt and evolve. For example, in the case of a changes to sensors, addition of new sensors, removal of old ones, previous analytical methods can be rendered obsolete. datagenous enables organizations to adapt to these changes among analytical methods and switch between them autonomously rather than though manual intervention.
8. govern and oversee data services
datagenous provides capabilities both for internal enterprise governance requirements, and for external digital asset management.
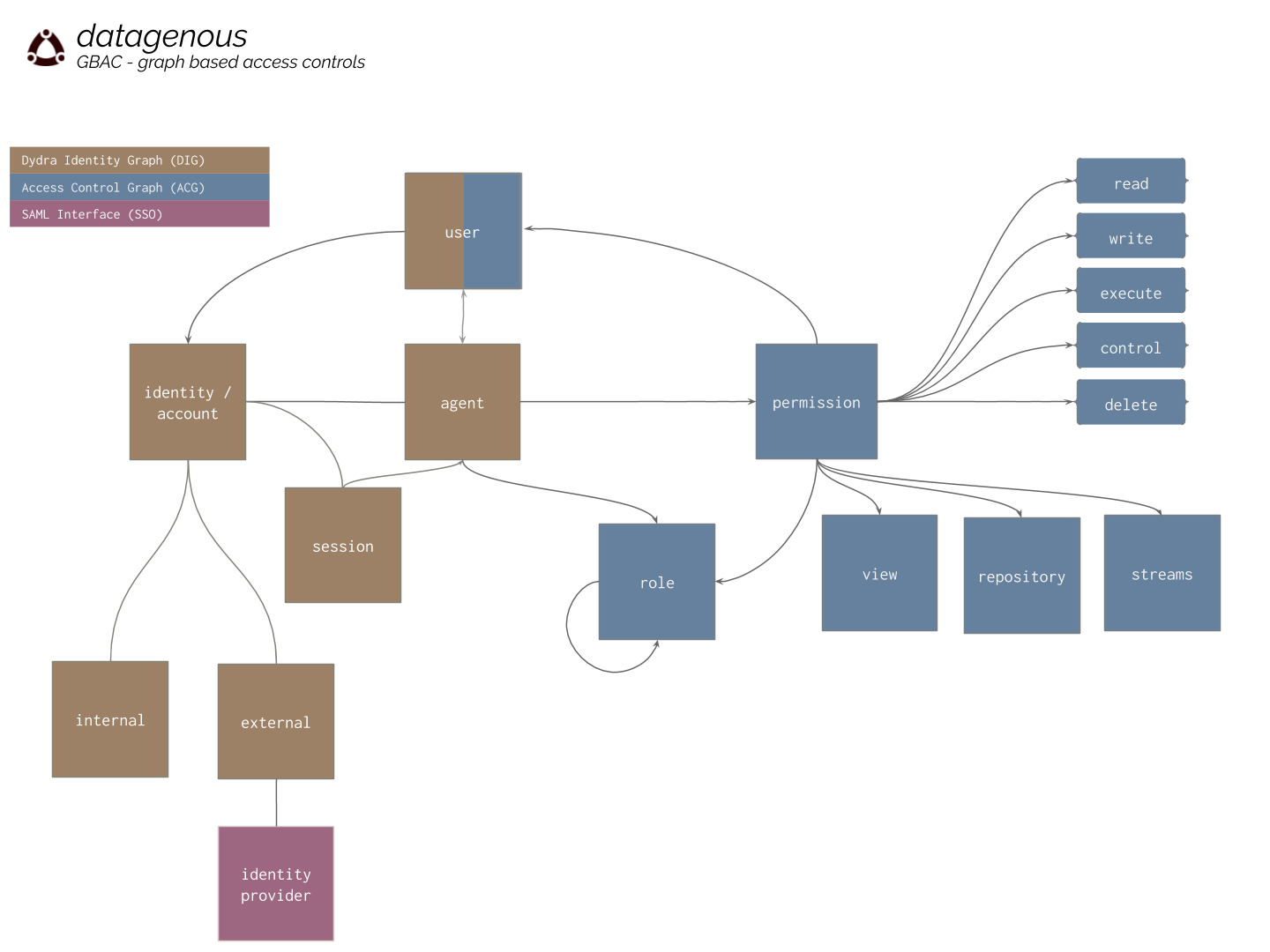
enterprise governance
datageno.us stores and manages identity, role, and authorization/permissions information as semantic graphs which supports a programmatic interface to specify agents and their access rights to system resources. The model supports controls such as those defined in role based access control (RBAC) systems with one key difference, the ability to use programmatic interfaces to specify access controls as opposed to total enumeration.
The datagenous service can be configured to integrate with third party identity providers via SSO/SAML. learn more: SSO support
SPARQL and GSP updates can generate records in the PROV-O vocabulary to record the provenance chain. learn more: data provenance
digital/data service asset management
datagenous can serve as a digital rights bank (DRB): a digital asset management (e-rights)/tokenization and extensible open contracting capability that provides a way to express and manage digital assets in a distributed information economy.
Contracts can be specified in datagenous as a collection of statements that describe the rules which govern a digital asset. Using datagenous, you can specify contracts and associate them with any digital asset or token by hashing the contract as part of the digital asset.
In addition to simple rules, policies may be limited by constraints (e.g., temporal or location constraints) and duties (e.g.payments, compliance actions) may be defined in relation to an asset.