the hidden cost of data centricity
In order to compete and succeed in business, you need to take full advantage of your data assets - even in a complex environment of rapid change, full of uncertainty, and risk. This requires faster and more adaptive integration across systems, and operationalization of data driven development such as AI and ML.
The “glue code” developed by organizations to address the challenges of data centric development such as ML constitutes at least 95% of a mature systems implementation. This is not sustainable.

what we enable
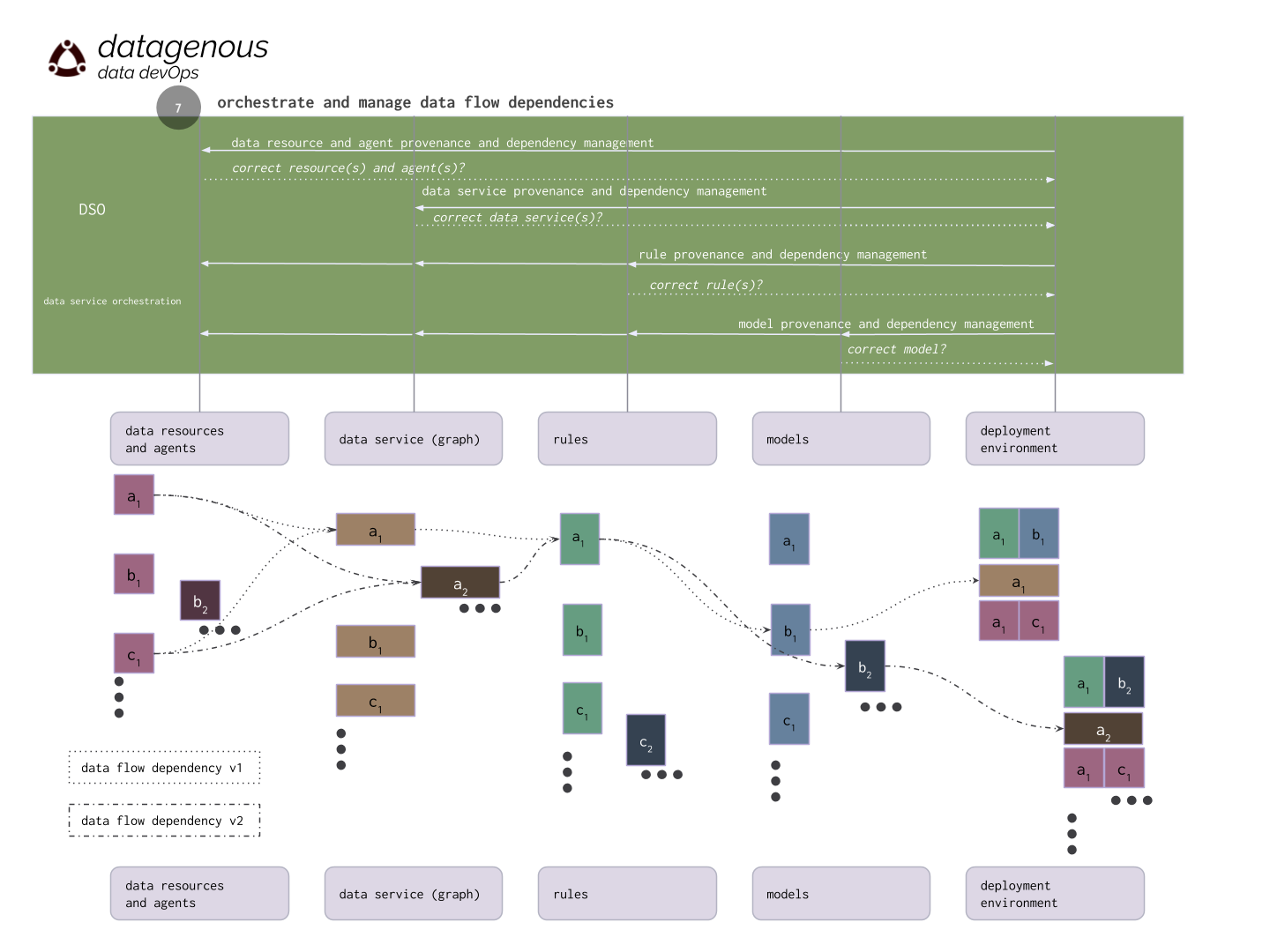
datagenous is a data devOps environment, delivered as a fully managed service, that enables teams to concurrently manage, integrate and semantically reconcile data resources with varying sample rates, from millisecond sensor streams to large archival data sets, on existing infrastructure while shifting opportunistically among centralized, federated, and distributed service deployment patterns.
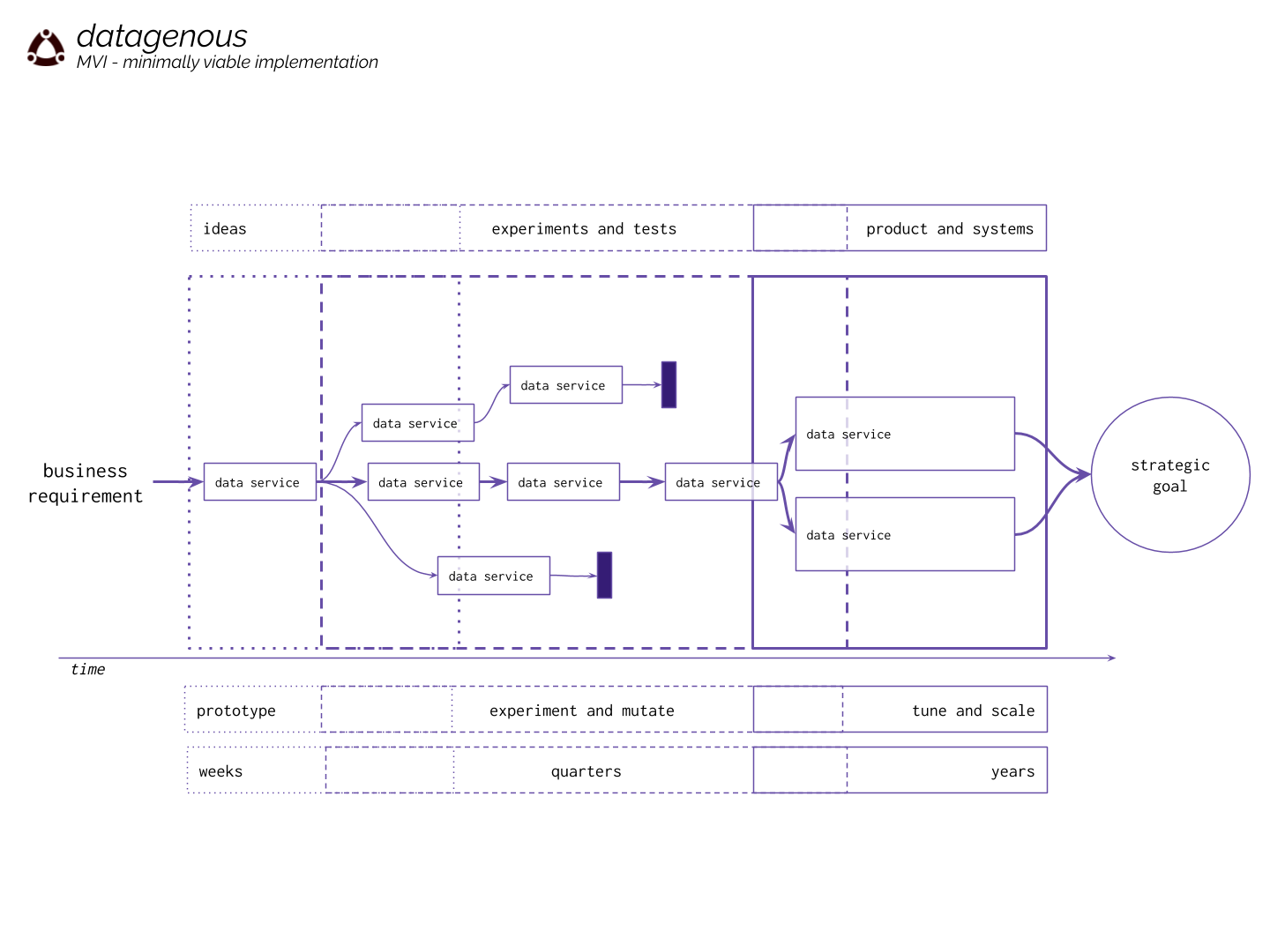
datagenous facilitates a process we call retrospective late binding (RLB), which inverts the traditional approach to data service development, to focus on business questions first. Your teams realize business requirements through minimally viable implementations, which don’t have to wait for the promise of a new capability or rely on expensive, fragile, opaque, and difficult to maintain ¨glue code¨.
low risk high return
datagenous helps you iteratively evolve data services, adhere to open standards, preserve modularity, and guide the infrastructural investment in big data as concrete incremental optimizations. Our data devOps technology has supported these processes to produce 10X comparative gains in ROI when compared to traditional data service design and integration.
what we are used for
datagenous is deployed in enterprises:
- to develop and operate industrial digital twin architectures for product ontogeny, genealogy, quality, and traceability
- to support the complex data transfers and provenance services to execute mergers acquisitions and spinoffs while minimizing the impact on business operations
- to integrate and manage heterogeneous evolving product lifecycle management (PLM) systems with business intelligence (BI) systems and architectures
- to develop and deploy edge analytics for intelligent industrial IoT manufacturing
datagenous also powers a free public dydra service for non profit, academic, and recreational work that supports over 1100 users and 2000 data services handling over 2,8 million requests in the last year.
where we are going
We are extending our service into ML. We are extending our interfaces into a JavaScript, collaborative data notebook programming environments. Our aim is to permit devOps teams to iterate and develop new ML complimented data services. We are looking for early adopters of this capability who have proof of concept applications they wish to realize.
We are developing the next iteration of a UX for our environment based in literate programming and direct manipulation principles and technologies (phosphorjs and jupterylabs) allowing domain experts to program and perform data experiments without coding, while preserving the ability for developers to access data workflows at whatever level of technical depth they require.